The biggest risk is not that AI sounds robotic. It is that it can sound persuasive before it is truly reliable.
Generative AI has introduced a new kind of advisor into the modern workplace.
It is fast, articulate, and confident.
But confidence is not the same as judgment.
Bad AI advice is not always obvious. Sometimes it sounds clear, confident, and persuasive before it proves unreliable.
The emerging risk of generative AI is not simply that it can produce incorrect answers. The deeper risk is that it can produce persuasive answers that are wrong in subtle ways—answers that sound convincing before they are truly reliable.
Generative AI can produce answers that sound confident and persuasive even when the underlying reasoning is incomplete or fragile.
This is why human judgment remains essential in the age of generative intelligence.
Key Insight
- The biggest AI risk is not obvious error, but persuasive wrongness.
- Fluent output can make weak reasoning feel decision-grade.
- The competitive edge is not better AI alone, but better judgment systems around AI.
A leader asks AI for guidance.
The answer arrives in seconds. It is clean, structured, and confident. It sounds like the work of someone who has read the market, understood the context, and thought carefully about the trade-offs.
That is exactly why the mistake is dangerous.
The modern risk of generative AI is not simply that it can be wrong. Every advisor can be wrong. Every analyst can miss a variable. Every forecast can fail.
The deeper risk is that AI can be wrong persuasively.
Researchers studying AI hallucinations and reliability challenges in large language models have also warned that fluent output can hide weak reasoning. It can make a weak recommendation feel strategically sound. It can compress uncertainty into fluency. And when that happens, the real failure is not only technical. It is human. We begin to confuse clarity of expression with quality of judgment.
That confusion matters now because AI is entering places where consequences are real: leadership decisions, hiring, operations, forecasting, prioritization, customer communication, and policy choices. In these settings, a confident answer is often not enough. What matters is whether the answer is grounded, contextual, and trustworthy. In an environment where information flows across search engines, AI systems, and discovery platforms simultaneously, the concept of Search Everywhere Optimization in the AI era becomes increasingly important.
A recent Harvard Business School Working Knowledge analysis on catching bad AI advice explains the issue in practical terms. In their experiments around AI-supported forecasting, participants often struggled most when familiar patterns and unusual conditions appeared together. The researchers found that simple alerts helped users decide when to trust the model and when to be more skeptical; a combined system of warnings and endorsements reduced errors by 49 percent.
That finding is important, but the larger lesson is even more important:
The AI era is not only a test of model quality. It is a test of human judgment quality.
As organizations increasingly integrate generative AI into strategic workflows—research, forecasting, hiring decisions, and operational planning—the central challenge is no longer technical capability alone. It is governance and judgment. The question leaders must answer is not simply what AI can do, but how human decision-makers should interpret and challenge AI-generated recommendations.
Why Bad AI Advice Sounds Persuasive
Generative AI is optimized to produce plausible language. It predicts what a useful answer should sound like. That makes it exceptionally good at a form of surface credibility.
A polished answer creates psychological pressure. We are more likely to trust what is well phrased, well structured, and delivered without hesitation. This is not because people are foolish. It is because human beings naturally use signals to estimate confidence and competence.
And AI now imitates many of those signals extremely well.
This is why the most dangerous AI output is often not the absurd one. Obvious nonsense is easier to reject. The more serious risk is the answer that is 80 percent reasonable, 20 percent unsound, and 100 percent confident.
That is enough to distort a meeting, influence a recommendation, or tilt a decision process in the wrong direction.
The HBS-covered research illustrates this through forecasting. The model can work well when data resembles what it has seen before, but it can break down when the situation becomes unusual, outdated, or outside its familiar range. In the study, participants performed especially poorly when they had to navigate both familiar and unusual data together, a pattern the authors describe as “naive adjusting behavior.”
That phrase deserves attention because it captures a broader executive risk. People do not always blindly obey AI. Often, they adjust it. But they adjust it badly. They over-trust where they should question, and under-correct where they should intervene.
In other words, the failure is not merely “AI made a mistake.”
The failure is: human-AI collaboration was poorly designed.
Research summarized by Harvard Business School Working Knowledge highlights how human users struggle to calibrate trust in AI systems when familiar and unusual patterns appear together.
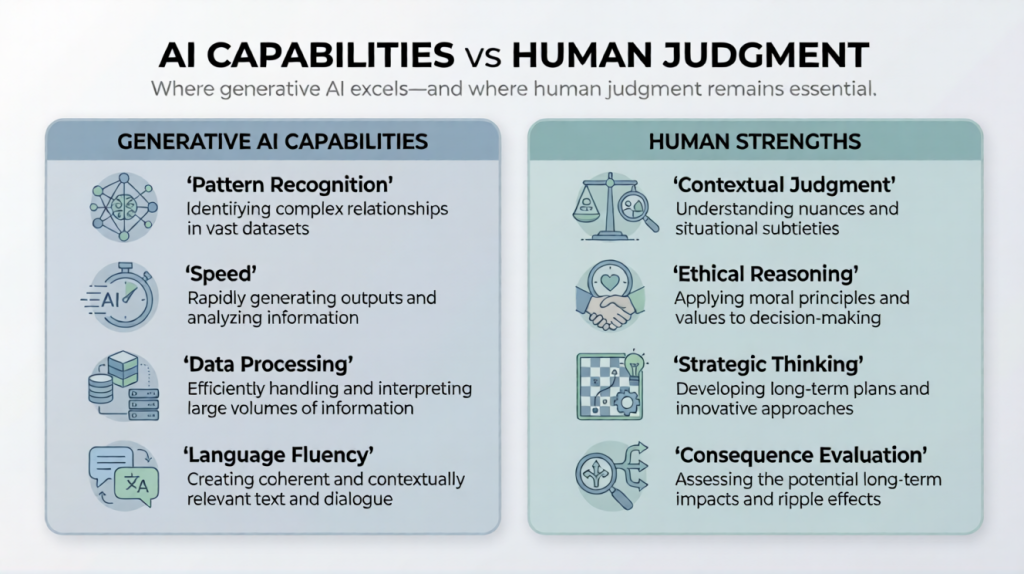
Why this matters beyond forecasting
It would be a mistake to read this as only a demand-prediction issue. The researchers themselves note that the core issue is making predictions about uncertain futures, and they point to applications across hospitals, banking, churn, turnover, manufacturing quality, supplier timelines, and conversion forecasting.
But the principle travels even further.
Whenever AI enters a decision environment, three questions appear:
Can the model recognize when the case is normal versus exceptional?
Can the user tell the difference?
Does the workflow make healthy skepticism easy or difficult?
Those questions apply to business strategy, content moderation, lead scoring, legal review, educational tools, and even editorial work. AI is often strongest in patterned, repeatable, high-volume contexts. It is often weaker at novelty, ambiguity, edge cases, and context that is not fully visible in the prompt.
That is why mature organizations should stop asking only, “How can we use more AI?”
A stronger question is:
Where is AI likely to be directionally helpful, and where is it likely to be persuasively wrong?
That is a more serious leadership question.
The new executive discipline: judgment architecture
For BBGK, this is the real insight.
The next phase of AI maturity will not belong to organizations that merely deploy models faster. It will belong to organizations that build better judgment architecture around those models.
Judgment architecture means the structures that help people evaluate machine output intelligently:
- prompts that expose assumptions,
- interfaces that signal uncertainty,
- review steps that force alternatives,
- workflows that distinguish routine cases from edge cases,
- leadership cultures that reward verification over speed theater.
The HBS research gives one practical example of this through warnings and endorsements. When users were told whether the AI was operating in familiar territory or not, they made better decisions. Endorsements alone reduced errors by 28 percent, warnings alone by 35 percent, and the combined approach by 49 percent.
That is not just a UX detail. That is a governance principle.
The lesson is that good AI adoption is not just model deployment. It is interpretive design.
At BBGK, much of our research explores how organizations build better decision frameworks at the intersection of technology and leadership, a theme discussed across the BBGK knowledge platform on AI, strategy, and human judgment.
The BBGK AI Advice Filter
This is where BBGK should contribute something original.
Rather than merely saying “be careful with AI,” we should give readers a usable framework. Here is the clearest one for this article:
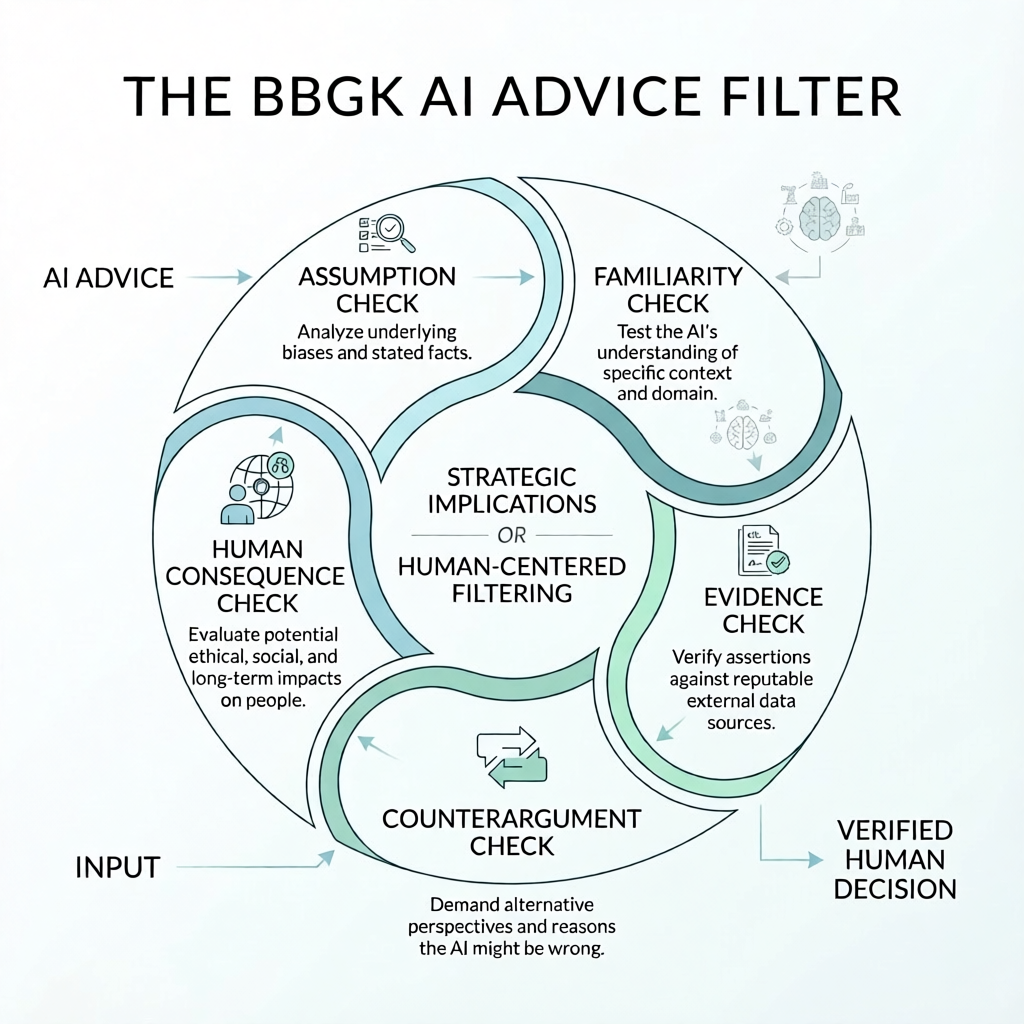
Definition: The BBGK AI Advice Filter
The BBGK AI Advice Filter is a five-step framework for evaluating AI-generated recommendations before they influence real decisions. The method helps leaders identify hidden assumptions, detect edge cases, verify supporting evidence, test counterarguments, and assess the human consequences of acting on AI advice.
1. Assumption Check
What must be true for this answer to be useful?
Every AI recommendation rests on assumptions, whether explicit or hidden. It may assume stable demand, comparable context, valid data, normal customer behavior, or complete information. Before accepting the answer, surface the assumptions.
2. Familiarity Check
Is this a routine case or an edge case?
The HBS-linked research is especially valuable here. AI tends to behave more reliably when the situation resembles representative data and less reliably when unusual or outlier conditions are involved.
If the case is novel, emotionally sensitive, high stakes, or context-heavy, skepticism should rise.
3. Evidence Check
What supports the recommendation?
Ask for the source logic, not just the conclusion. What evidence, examples, data, or mechanism supports the answer? If the response cannot be grounded, it should not be treated as decision-grade.
4. Counterargument Check
What would make this advice fail?
A strong recommendation should survive pressure. Ask the model for the strongest objections, the edge-case breakdowns, and the conditions under which the advice becomes weak.
5. Human Consequence Check
What happens if this is wrong?
This is the most human question and often the most neglected. A low-cost drafting error is not the same as a strategic, financial, legal, reputational, or human-harm error. The greater the consequence, the stronger the human review should be.
This framework turns AI from an answer machine into a thinking instrument.
That is the correct relationship.
Why leaders must resist fluent certainty
There is a subtle cultural risk emerging around AI. Speed is becoming performative. Research on collaborative intelligence between humans and AI has consistently shown that the strongest outcomes occur when human judgment and machine capability complement each other rather than replace one another.
Quick output can create the impression of sophistication. Teams may start appearing productive while becoming less rigorous. Leaders may begin valuing acceleration before evaluation.
That would be a strategic mistake.
Because the purpose of intelligence inside an organization is not to generate language faster. It is to improve judgment.
If AI helps generate options, summarize complexity, and expose blind spots, it is valuable. If it encourages premature closure, borrowed certainty, and uninspected reasoning, it becomes dangerous.
This is why the most future-ready leaders will not be the ones who trust AI the most. They will be the ones who know when not to.
The mature stance is neither fear nor worship.
It is disciplined partnership.
Use AI for scale.
Use humans for discernment.
Use systems to make that boundary visible.
Where technology meets humanity
This is not only a technical conversation. It is a human one.
Technology changes speed. It changes access. It changes the shape of work. But it does not remove the burden of responsibility. It may actually increase it.
As AI becomes more articulate, people must become more discerning.
As AI becomes more integrated, leaders must become more deliberate.
As AI becomes more persuasive, human beings must become more awake to the difference between an answer that is polished and an answer that is earned.
That may be the central discipline of this era.
Not simply learning how to use AI.
But learning how not to be misled by it.
And in that sense, the future will not belong to the people who automate everything.
It will belong to the people who still know how to judge.
This becomes especially important at the point where AI shifts from assisting judgment to carrying too much authority — a boundary explored further in the AI Decision Boundary Framework 2026
BBGK — Beyond Boundaries Global Knowledge
Where technology meets humanity.
What Leaders Should Do Instead
Leaders should not treat AI output as decision-grade by default. They should build review conditions around it.
That means:
- using AI first for options, not authority
- separating routine cases from edge cases
- requiring evidence before acting on recommendations
- designing workflows that make skepticism easy
- increasing human review as stakes, ambiguity, and consequence rise
The point is not to slow everything down. It is to prevent fluent output from bypassing judgment.
If You Have Any Questions on Bad AI Advice
How should leaders verify AI recommendations before acting on them?
Leaders should treat AI recommendations as analytical inputs rather than final conclusions. A practical approach is to apply a structured verification process: identify the assumptions behind the answer, determine whether the situation is routine or unusual, examine the evidence supporting the recommendation, explore counterarguments, and evaluate the consequences if the advice turns out to be wrong. This type of review process helps transform AI from an answer generator into a decision-support tool.
How can decision-makers catch bad AI advice?
Decision-makers can catch bad AI advice by checking assumptions, asking whether the case is routine or unusual, verifying evidence, testing counterarguments, and increasing human review when the consequences are high. Research covered by Harvard Business School suggests that users perform better when AI systems provide clear signals about when outputs are more or less trustworthy.
Why does AI sometimes sound right even when it is wrong?
Generative AI is optimized to produce plausible language, not guaranteed truth. That means it can generate fluent, confident responses even when the underlying reasoning is weak or the context is incomplete. The HBS article emphasizes that AI can sound confident even when it lacks the information needed for reliable recommendations.
When should leaders trust AI recommendations?
Leaders should place more trust in AI when the task is patterned, repeatable, and close to representative data. They should apply more skepticism when the case is unusual, ambiguous, emotionally sensitive, or high stakes. The HBS-covered research found that alerts about familiar versus unfamiliar territory helped users calibrate trust more effectively.
What is the biggest leadership risk with generative AI?
The biggest leadership risk is not only factual error. It is over-trusting persuasive but weak output and letting fluent language replace careful judgment. This risk grows when organizations adopt AI faster than they build review systems around it.
The most important leadership skill in the AI era will not be writing better prompts. It will be building better systems for judging the answers.
This becomes especially relevant in agentic search SEO, where AI systems may increasingly select, compare, call, summarize, or act before the user ever visits a business website.
